1. 테이블 로깅하기
- 테이블 만들기
- Pandas Dataframe
새 Table을 만들고 로깅하려면 다음을 사용합니다.
wandb.init(): 결과를 추적할 run을 생성합니다.wandb.Table(): 새 테이블 객체를 생성합니다.columns: 열 이름을 설정합니다.data: 각 행의 내용을 설정합니다.
wandb.Run.log(): 테이블을 로깅해 W&B에 저장합니다.
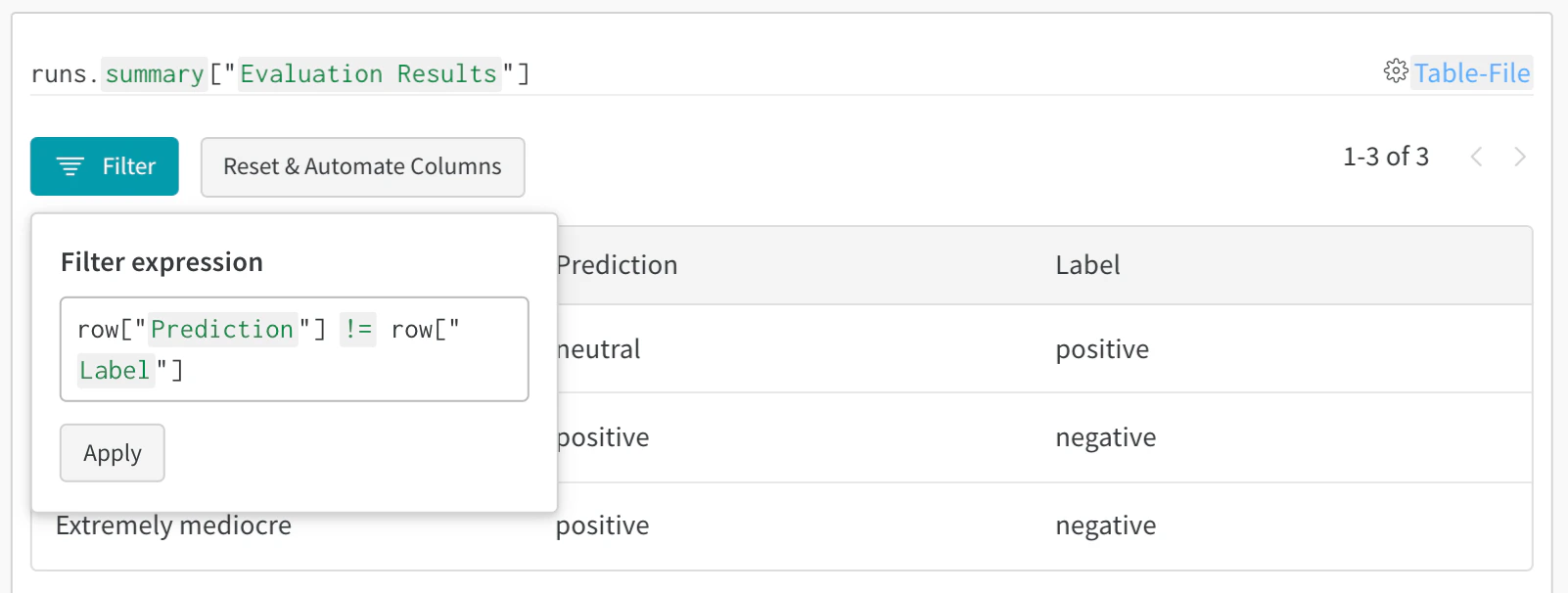
2. 프로젝트 워크스페이스에서 테이블 시각화하기
- W&B App에서 프로젝트로 이동합니다.
- 프로젝트 워크스페이스에서 run 이름을 선택합니다. 고유한 각 테이블 키에 대해 새 패널이 추가됩니다.
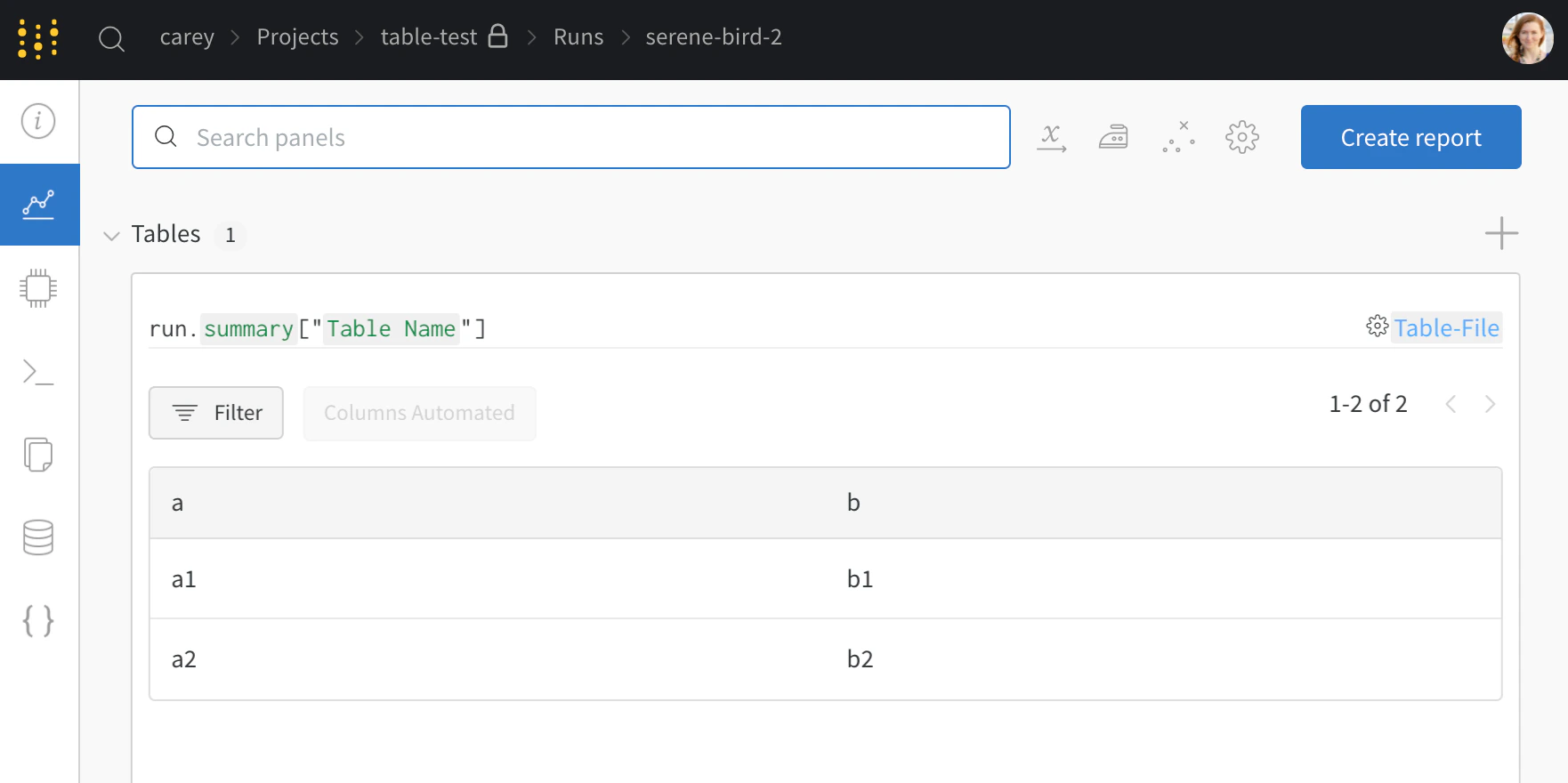
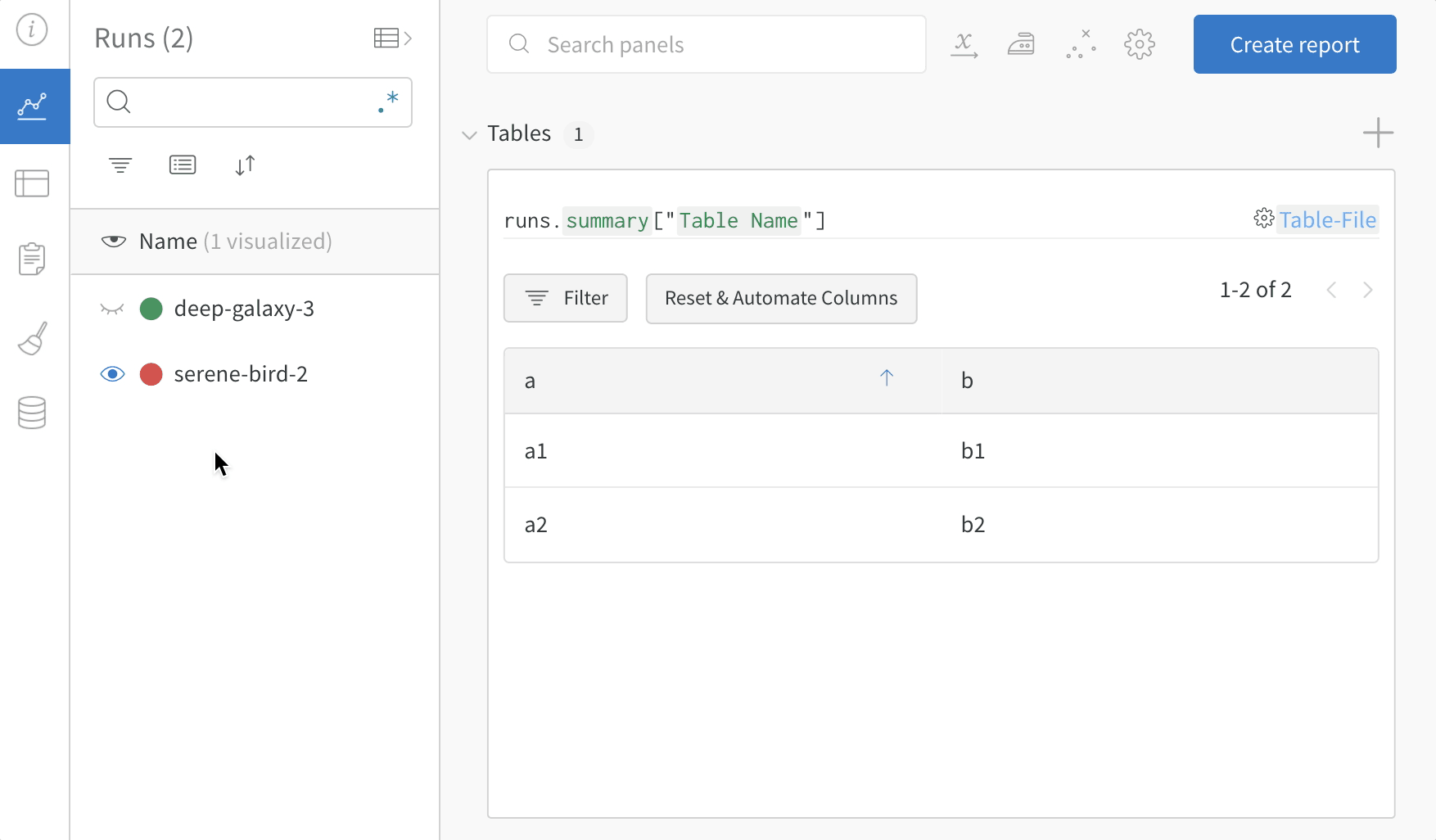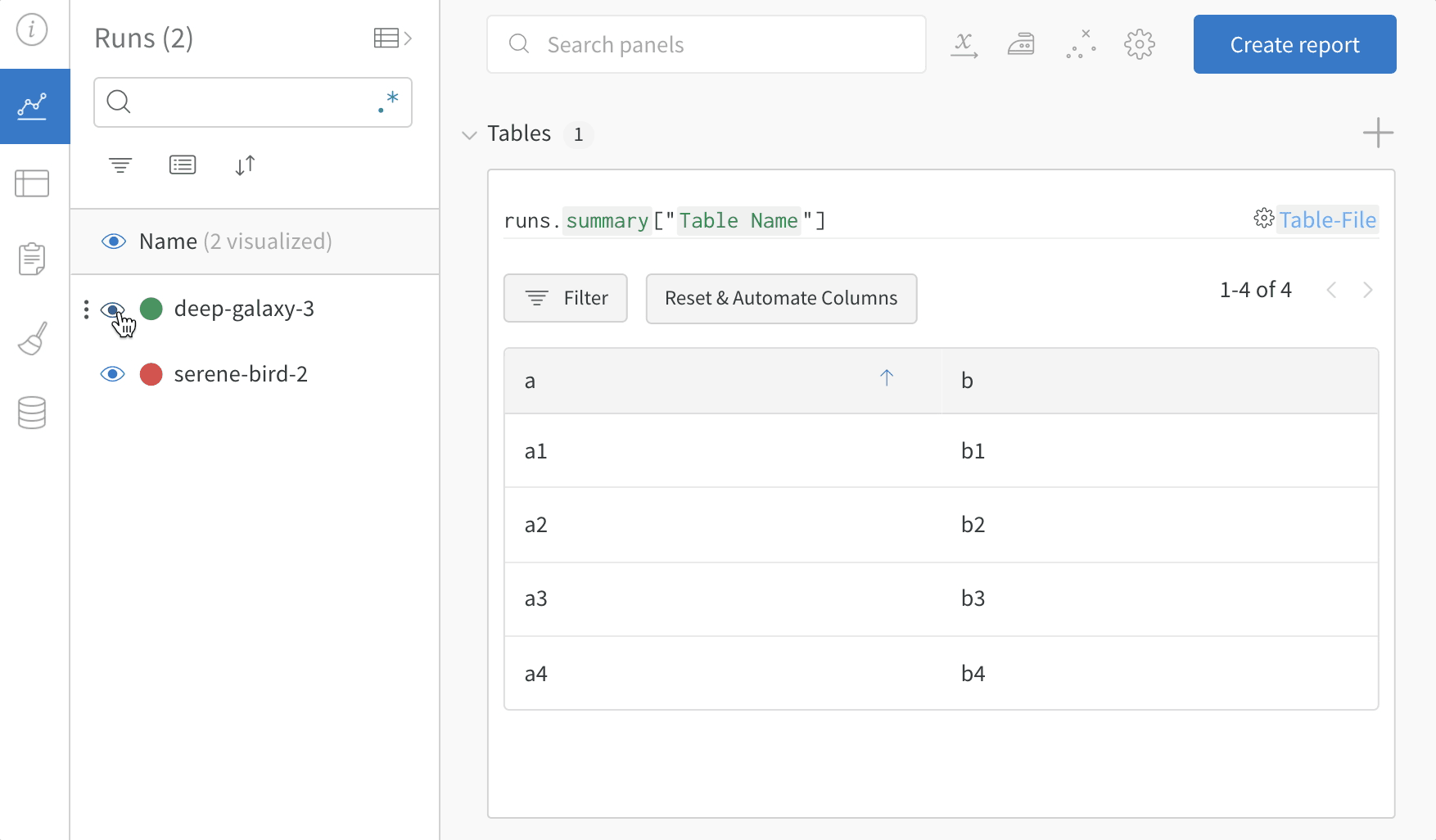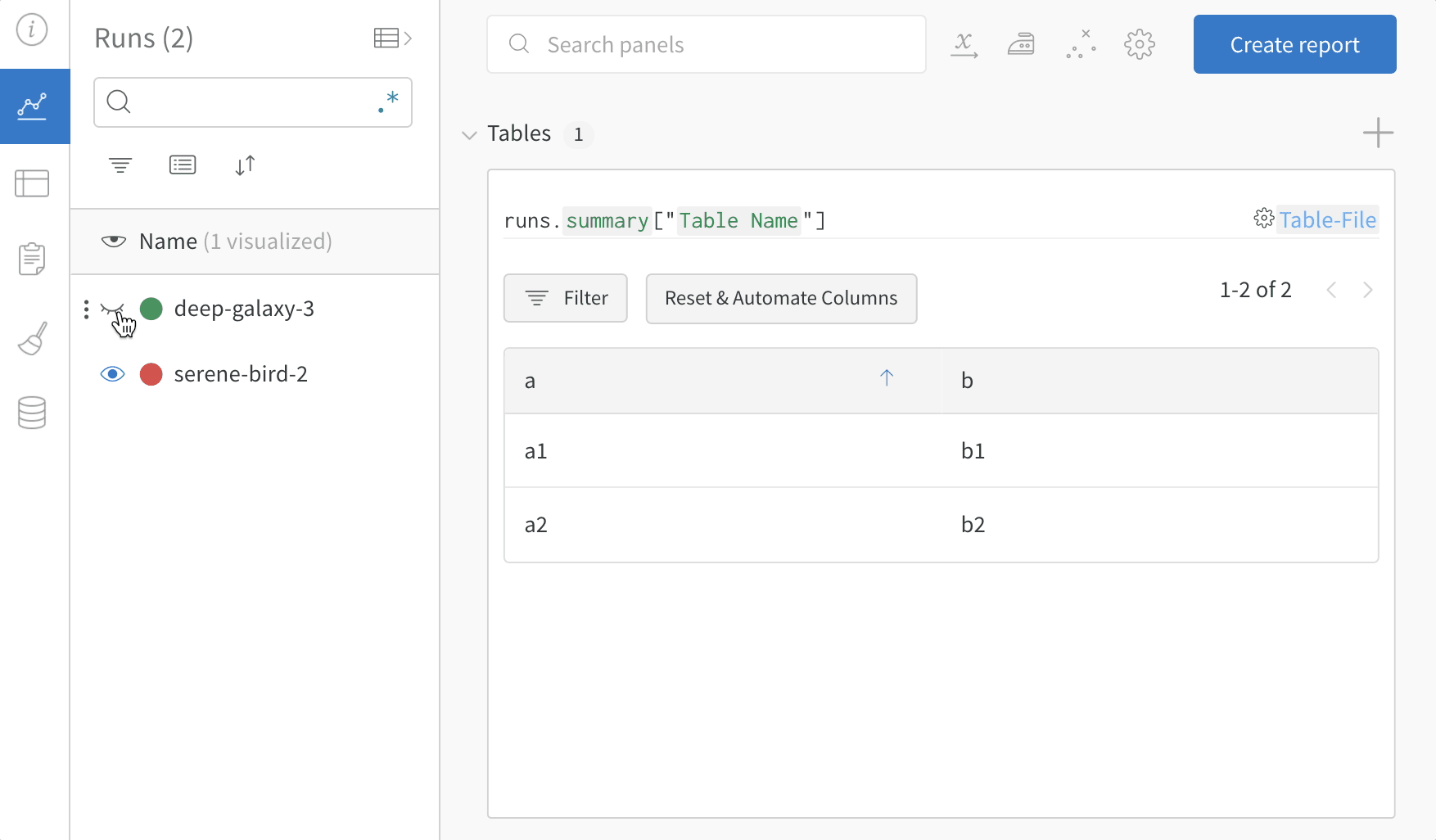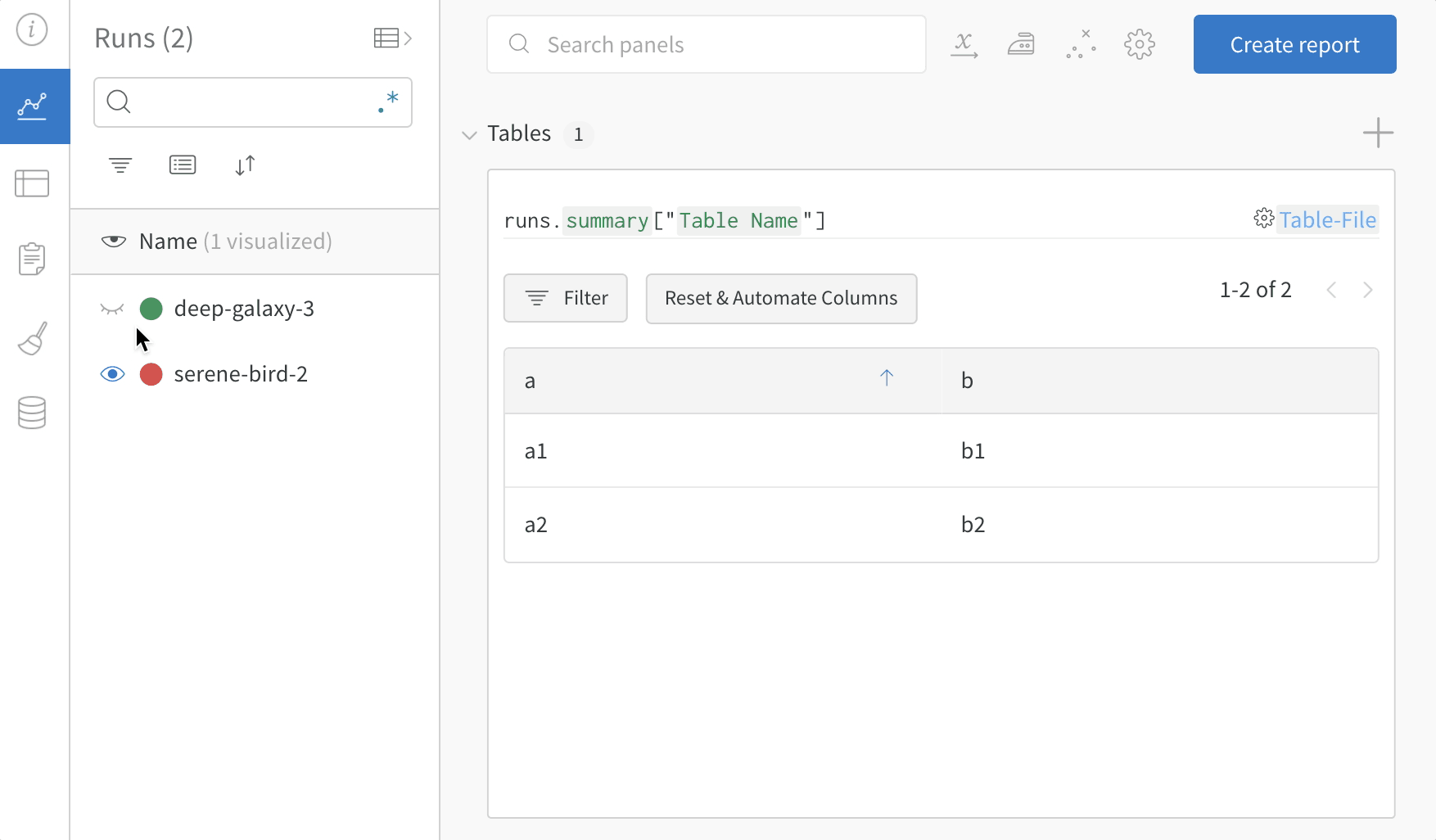
my_table은 "Table Name" 키로 로깅됩니다.
3. 여러 모델 버전 비교하기